Engine: Chapter 1 - Core Design

In this chapter, we'll explore an architecture for the engine which will provide the features necessary to build what we described in the prologue: a lightweight, flexible, extensible core that serves as the foundation for composing a variety of modules together to build custom solutions.
Pluggable Core
We are going to start with a micro kernel style architecture. By itself, the engine will provide little functionality that stands alone, but will instead focus on providing functionality that centers around plugins (e.g. execution, event routing) and facilitating cross cutting concerns (e.g. configuration, container, core logging, HID functionality). Plugins will then provide the bulk of the functionality for a configured setup.
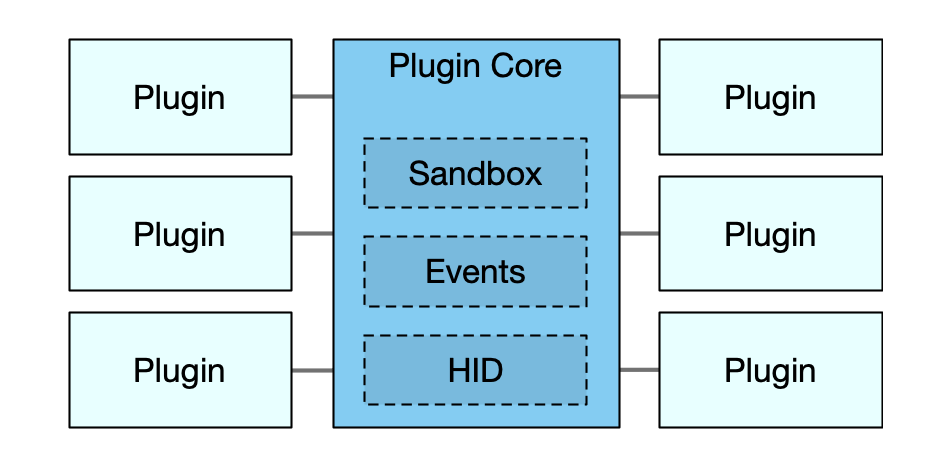
One of the most basic functions that the core needs to perform is the loading plugins. An obvious way for that to be accomplished would be to specify NPM packages to load and then require() them to load their functionality. However, we can make both plugin development and deployment more flexible by not relying on module installation and linking.
We can start with dynamically discovering plugins in configured directories on the local filesystem and this could be done directly, however we're going to introduce another interface layer that will add flexibility to our plugin loading.
Sources
We are going to create a new layer called a "source", which will serve as the bridge between the engine and the plugins it uses. Sources handle the discovery, retrieval, and the loading of plugins. By abstracting sources, the engine remains agnostic of the underlying storage or delivery mechanism.
This allows developers to:
- Seamlessly switch between sources (e.g., local to remote) without changing core engine logic.
- Add new sources, such as cloud-based plugin registries, without disrupting the existing architecture.
Example Sources
- Local Directory: A folder on the file system where plugins are stored. This is ideal for development or when plugins are managed manually.
- Network: Plugins hosted on a remote server, similar to a package registry like npm. These are useful for distributing plugins across different environments.
We will start with local plugin directories and eventually extend the system to fetch plugins from other sources (e.g. network), handle different formats (e.g. zip, tgz), support hot reloading (👀) and more.
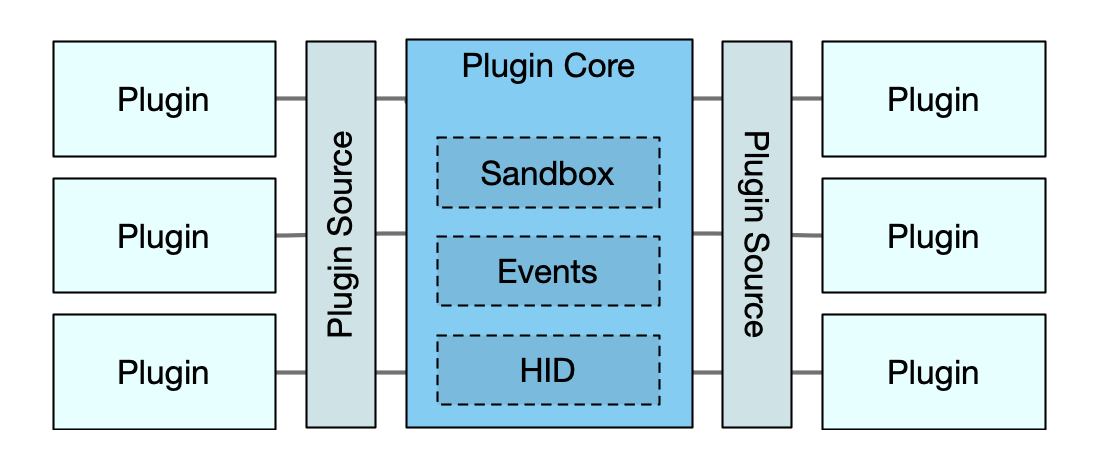
Sources will have similar life cycles as the plugins themselves (configuration, initialization, startup and shutdown) with the addition of supporting list and fetch operations.
Structure
Let's provide an example structure for a simple plugin, which prints out a log message on an interval. The plugin can be an NPM package with the dependencies it needs and at this point written in any language that can target JavaScript. In this example, our plugin is developed in TypeScript.
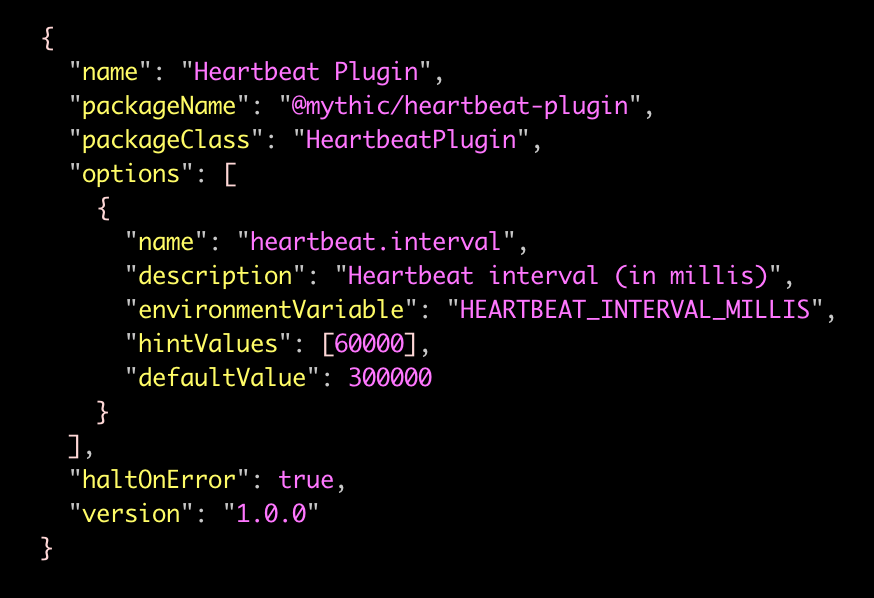
We will also include a plugin.json file, which contains metadata for the plugin. This metadata provides the necessary details like the display name, the package name, the class to load, and available configuration options. Later, we'll also be able to surface this information to users of the system in various ways. Here's an example plugin.json:
Our plugin code will need to implement an interface that the core can use to interact with the plugin. Each plugin will implement this interface and allow it to participate in lifecycle events (e.g. receive configuration, initialize, start, stop, receive events).
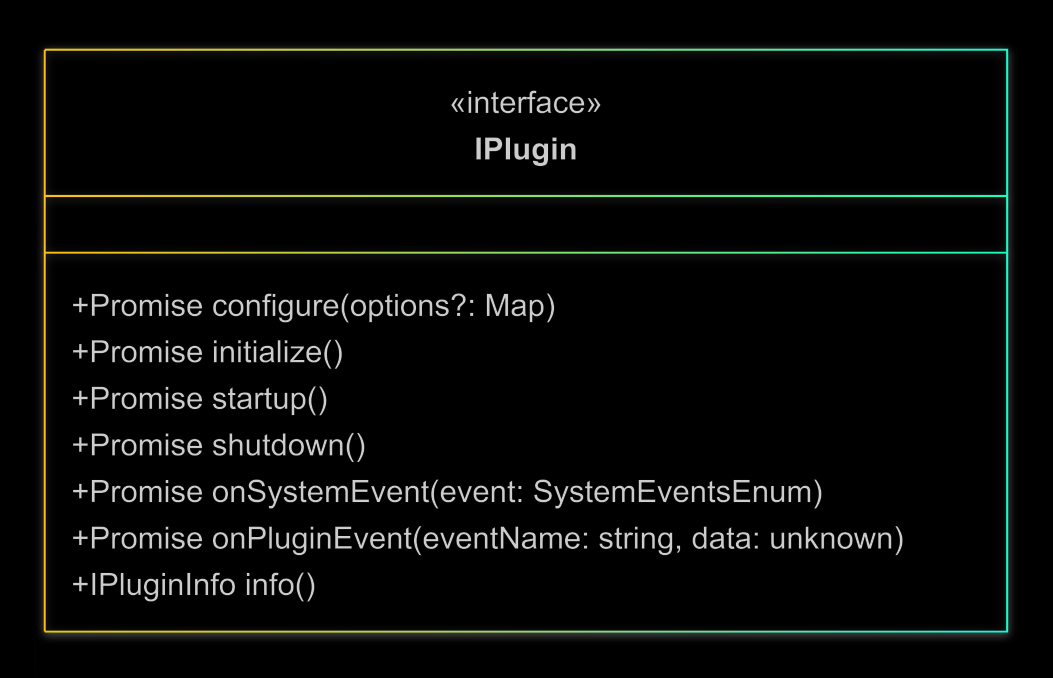
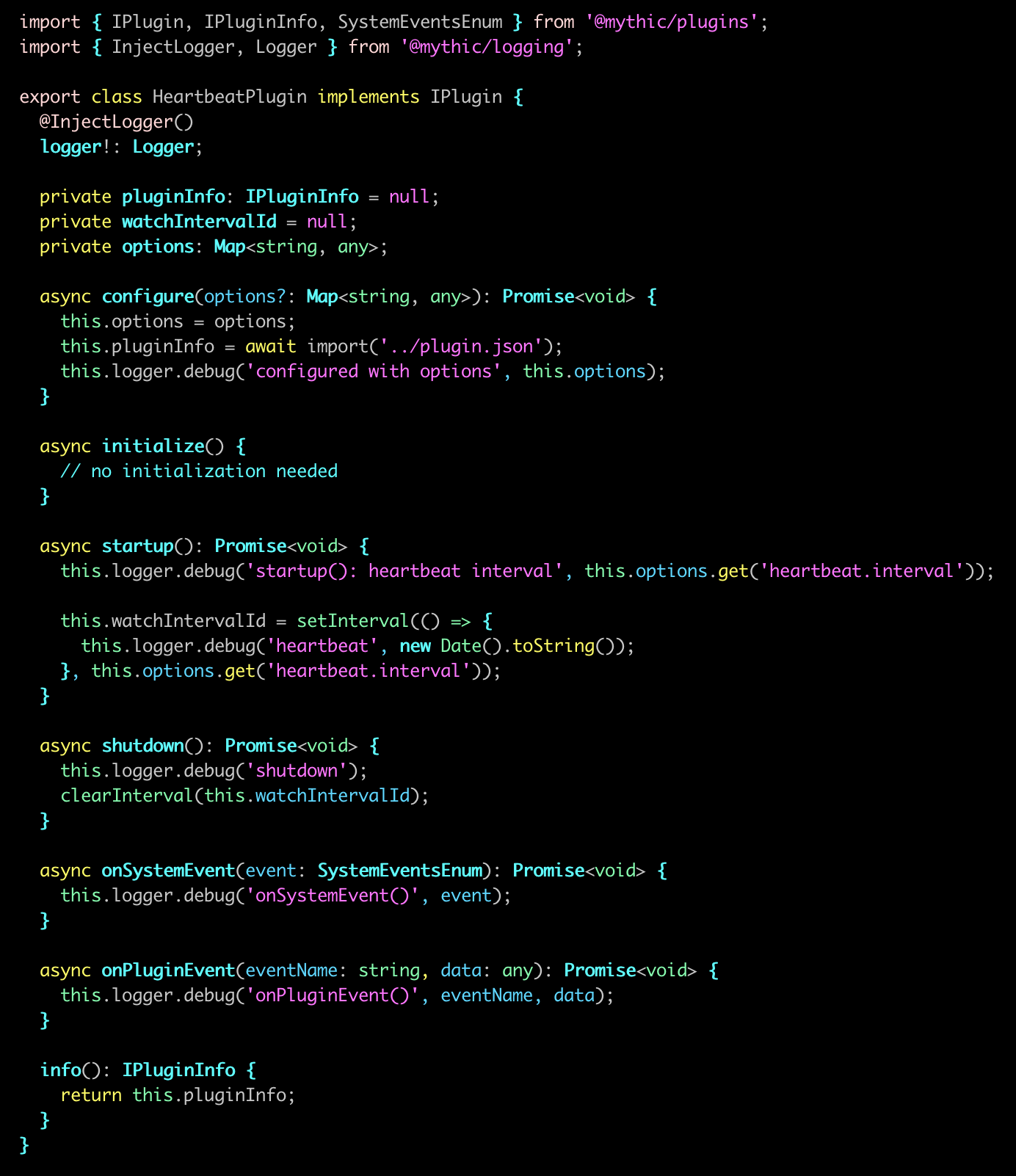
And here's a really basic example for our HeartbeatPlugin we've described:
Configuration
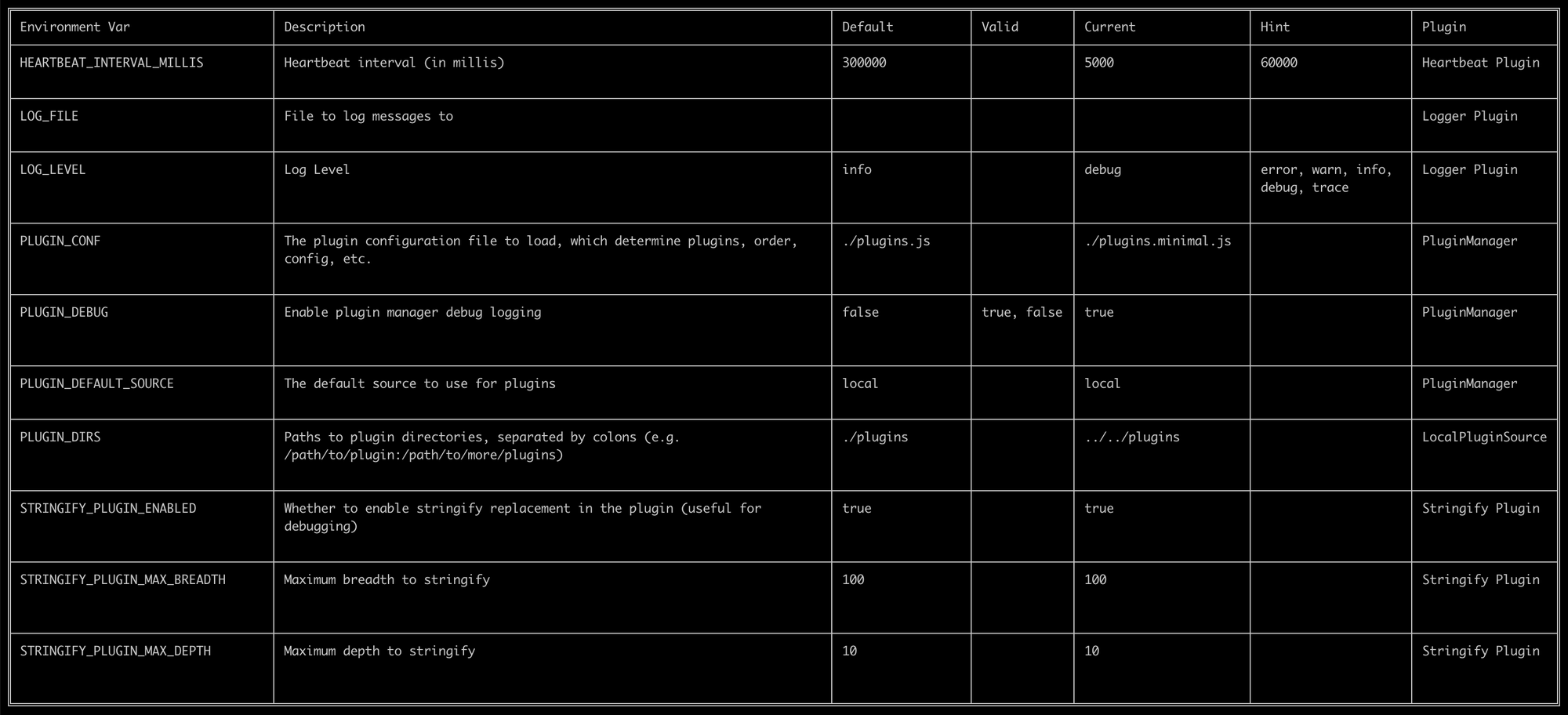
We want to be able to customize a list of plugins and provide any desired static configuration, which may then be overridden through environment variables. As seen in our sample plugin.json, an option has a name (e.g. heartbeat.interval) which can be referenced in the configuration file and inside the plugin as well as an environment variable the system will override that configuration with. The parsing of those values will be automatically handled and made available to the plugin at runtime.
And once we've configured the relevant plugins to be activated, we want to be able to easily provide an overview of this configuration information directly to users within various interfaces (logs, CLI, web, etc.) This will provide in-stream configuration documentation based on what the plugins themselves expose and how the current environment is configured. We will also want to ensure that some config values can be marked sensitive, so that the values are never printed (e.g. passwords).
Context
To pass around contextual data in threads of work without passing it via functions signatures, we will need to maintain some form of context. Some folks will think of the common use case to maintain request or session data. Key Features of Context Handling include:
- Isolation: Each plugin can maintain its own context while still accessing shared data, ensuring modularity.
- Scoping: Contexts can be global (shared across plugins) or local (specific to a plugin or task).
- Lifecycle Management: The engine creates and cleans up contexts as plugins are initialized or unloaded.
Effective context handling enhances modularity, reduces tight coupling, and ensures the engine and plugins operate cohesively. Maintaining this context data is another critical feature we will want to handle and leverage within the core.
Logging
There are lots of varied needs in logging and we don't want to implement them all, however providing a core logging implementation which has adapters that bridge to specific logging implementations (e.g. winston, pino, log4j, etc.) will prove useful. Implementations can be used directly and the core can be configured to log via the same systems, or one could leverage the logging within the core and swap adapters as logging needs change.
There are a number of features related to logging which we can provide, including: log injectors, log formatting, replacing console.* methods to route via adapters, decorators for grouping, indentation, etc.
Container
Direct code dependencies between components works in many use cases, however sometimes we need to share object instances (e.g. singletons) or integrate some type of IOC / Dependency Injection patterns. Providing a baseline implementation to support these use cases should also be considered.
The system should allow for implementations to leverage existing libraries that are already in common use, and we want to ensure that there is a low barrier to entry.
User Interfaces
Another common need we'll run into is the routing of human interface requests and responses to and from different interactive User Interfaces (e.g. CLI, Web, Desktop). We want to surface data and operations from the system into configured user interfaces.
Examples:
- Dynamically configure our example heartbeat interval at runtime
- Items that require administrative approval (e.g. lossy data changes)
- Expose data from our logging or telemetry plugins
There are a number of common use cases which could be supported through some baseline user interface functionality within the core.
Next
We'll dive into more details on the each of the functionalities we want the core to provide: plugin loading, configuration, logging, user interfaces, containers and more.